La visualización de caja y bigotes ofrece una vista de la media y la mediana junto con cuatro cuartiles para identificar valores atípicos estadísticos. Esta es la segunda parte de una serie de tres sobre las herramientas de distribución de datos de Bing.
Hoy, para aprovechar nuestro conocimiento práctico de las distribuciones de datos, analizaremos los datos de CPC utilizando diagramas de caja y bigotes. Si se perdió la primera entrega, póngase al día con los histogramas y reúnase con nosotros aquí.

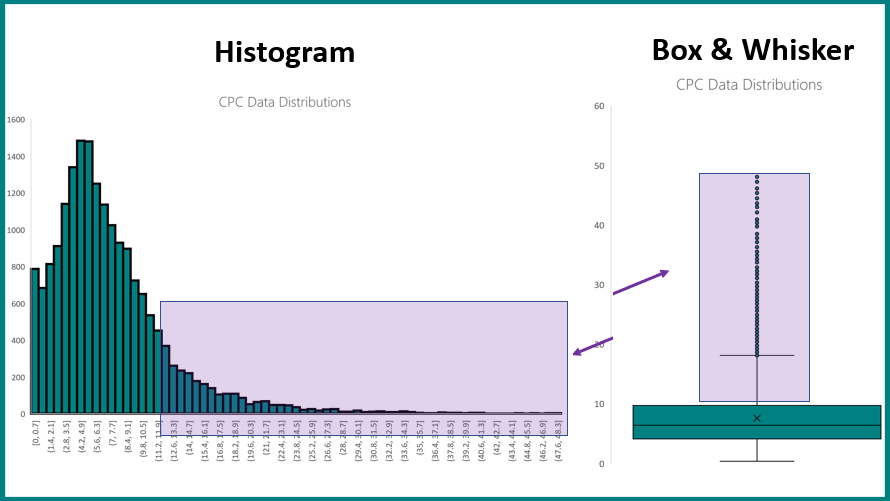
Si ha terminado la primera parte de esta serie, el histograma de la izquierda le resultará familiar. El gráfico de la derecha es un gráfico de caja y bigotes, creado a partir del mismo conjunto de CPC que usamos en la primera parte. ¡Hurra por la continuidad!
Primero, vamos a basarnos en algunos conceptos básicos. Debido a que no segmentamos nuestros datos de ninguna manera y, por lo tanto, usamos solo una distribución, el valor de CPC se expresará en el eje y, y el eje x será nulo.

Ahora, repasemos los componentes del diagrama de caja y bigotes. Primero que nada, la x.

Esta x representa el valor medio de la distribución, que reconocerá como el promedio simple asociado a menudo con sus datos de búsqueda. Para los propósitos de este ejercicio, la X es su CPC promedio. Con ese fin, la línea en el medio del cuadro representa la mediana.

Si bien obtener tanto la media como la mediana de la distribución en la visualización es una característica maravillosa del diagrama de caja y bigotes, los cuatro cuartiles pueden ayudar a adivinar mucha información que no podemos obtener a través de un histograma.

El umbral inferior del cuadro (o el umbral más a la izquierda para una gráfica justificada horizontalmente) es el cuartil inferior, o primer cuartil, o Q1, y representa el número tal que el 25 por ciento de las observaciones son menores y el 75 por ciento son mayores . En este contexto, piense en una «observación» como un único punto de datos.

El umbral superior del cuadro (o el umbral más a la derecha para una gráfica justificada horizontalmente) es el cuartil superior, o tercer cuartil, o Q3, y representa el número tal que el 75 por ciento de las observaciones son menores y el 25 por ciento son más grande.
Siguiendo esta misma notación, también puede inferir que la mediana sirve como el segundo cuartil, dado que el 50 por ciento de las observaciones son mayores y el 50 por ciento son menores.
Es cierto que esto puede volverse un poco confuso de seguir. Hemos descubierto que algo que ayuda con la intuición es pensar que los cuartiles poseen rangos y recordar que cada rango contiene aproximadamente una cuarta parte del total de puntos de datos en el conjunto de datos. Quizás esta búsqueda sería mal vista por los puristas estadísticos del mundo, pero tenemos una visión brillante de todo lo que le ayude a aprender. Es de esperar que la imagen siguiente ayude a conceptualizar.

Ahora estamos llegando a alguna parte, ¿verdad? Podemos observar que los tres primeros rangos de cuartiles de esta distribución tienen un rango de valores bastante comparable. Pero el rango del cuarto cuartil es un trazo mucho más amplio. Para que este anunciante reduzca sus CPC, una táctica enfocada y precisa sería aislar las palabras clave que se encuentran dentro del rango del cuarto cuartil y modificar las ofertas correspondientes.
Muy bien, pero ¿qué pasa con esos puntos?

Los puntos de datos que se representan como puntos individuales pueden considerarse valores atípicos estadísticos en el contexto de una distribución de datos. En nuestro escenario hipotético, el anunciante busca tácticas para mitigar el costo de CPC. Además del rango del cuarto cuartil, este anunciante debe investigar las palabras clave responsables de estos valores atípicos y actuar en consecuencia.
Vuelva a escuchar la primera parte de esta serie por un momento y recuerde que nuestra distribución es de cola derecha, lo que significa que el sesgo es hacia valores que son mayores que la mediana. Sabiendo lo que sabe ahora sobre histogramas y diagramas de caja y bigotes, debería poder intuir la relación entre estas dos visualizaciones de los mismos datos.

En la parte final de esta serie, exploraremos el uso de distribuciones para identificar cambios en sus datos a lo largo del tiempo.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a El Blog informatico. Los autores del personal se enumeran aquí.