¿Se puede aplicar el aprendizaje automático a sus cuentas de PPC para hacerlas más eficientes? El columnista David Fothergill describe cómo utilizó el aprendizaje automático para encontrar nuevas palabras clave para sus campañas.

Un desafío clave cuando se trabaja en lo que podríamos denominar cuentas de PPC “a gran escala” es la eficiencia. Siempre habrá más que podría hacer si tuviera una cantidad ilimitada de tiempo para crear y optimizar una campaña de AdWords; por lo tanto, el truco está en administrar las prioridades y ser eficiente con su tiempo.
En esta publicación, hablaré sobre cómo los conceptos del aprendizaje automático podrían aplicarse para ayudar con la parte de la eficiencia. Usaré la categorización de palabras clave como ejemplo.
Parafraseando a Steve Jobs, una computadora es como «una bicicleta para la mente». El significado generalmente entendido de esta declaración es que, de la misma manera que una bicicleta puede aumentar la eficiencia de la locomoción impulsada por humanos, las computadoras pueden aumentar la productividad y el rendimiento mental humanos.
Con el existencialismo fuera del camino, vayamos a algo tangible: exploraremos aquí cuán relevante / valioso podría ser intentar automatizar el proceso de colocar nuevas frases clave en una campaña existente.
¿Qué entendemos por aprendizaje automático?
Como una especie de definición que se vincula con nuestros objetivos, consideremos que lo siguiente es cierto:
Aprendizaje automático es un método utilizado para idear modelos / algoritmos que permitan la predicción. Estos modelos permiten a los usuarios producir decisiones fiables y repetibles y resultados al aprender de las relaciones históricas y las tendencias en los datos.
El beneficio de las “decisiones confiables y repetibles” es el valor exacto que nos interesa lograr en este caso.
En un nivel muy alto, el objetivo de un algoritmo de aprendizaje automático es generar una fórmula de predicción y coeficientes relacionados que se ha encontrado para minimizar el «error», es decir, se ha encontrado rigurosamente que tiene el mayor poder predictivo.
Los dos tipos principales de problemas resueltos por las aplicaciones de aprendizaje automático son la clasificación y la regresión. La clasificación se relaciona con predecir qué etiqueta se debe aplicar a los datos, mientras que la regresión predice una variable continua (el ejemplo más simple es tomar una línea de mejor ajuste).
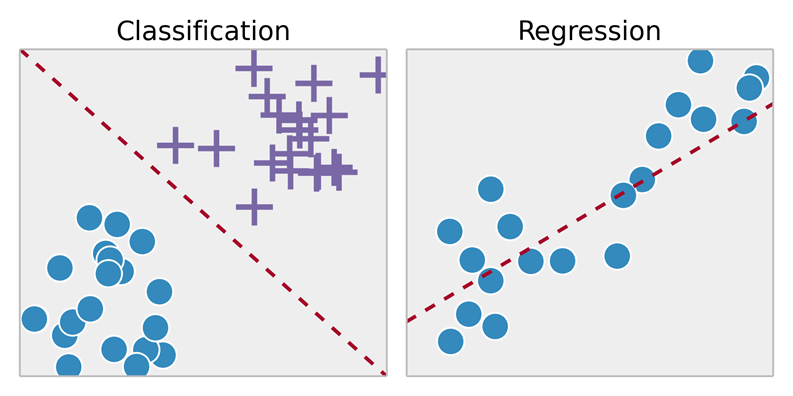
Categorización de palabras clave como un problema de «clasificación»
Con esto en mente, mi objetivo es mostrar cómo se puede usar la clasificación de texto para decidir mediante programación dónde se pueden colocar las frases clave recién aparecidas (por ejemplo, de los informes de consultas de búsqueda regulares). Este es un ejercicio trivial, pero importante, y puede llevar mucho tiempo mantenerlo al tanto cuando tiene una cuenta de cualquier escala.
Un requisito previo principal para resolver un problema de clasificación son algunos datos ya clasificados. Dado que una cuenta de búsqueda paga existente tiene palabras clave «clasificadas» por la campaña en la que se encuentran, este es un buen lugar para comenzar.
El siguiente requisito son algunas «características» que se pueden utilizar para intentar predecir cuál debería ser la clasificación de los nuevos datos. Las «características» son esencialmente los elementos sobre los que se construye un modelo: las variables predictoras.
La forma más sencilla de transformar datos de texto en una característica que sea útil para un algoritmo es crear un vector de «bolsa de palabras». Este es simplemente un vector que contiene un recuento del número de veces que existe una palabra en un documento dado. En nuestro caso, tratamos una palabra clave como un documento muy, muy breve.

Nota: En la práctica, debido a que nuestros «documentos» (es decir, palabras clave) son cortos, podríamos terminar con un conjunto de vectores que no es lo suficientemente significativo debido a la falta de diversidad, pero está fuera del alcance de este artículo profundizar más en esto. .
Seleccionar un algoritmo adecuado
Existe una amplia gama de enfoques algorítmicos diferentes para resolver una amplia gama de tipos de problemas. La siguiente imagen ilustra esto y también muestra que existe una cierta lógica subyacente que puede ayudarlo a dirigirse hacia una elección adecuada.
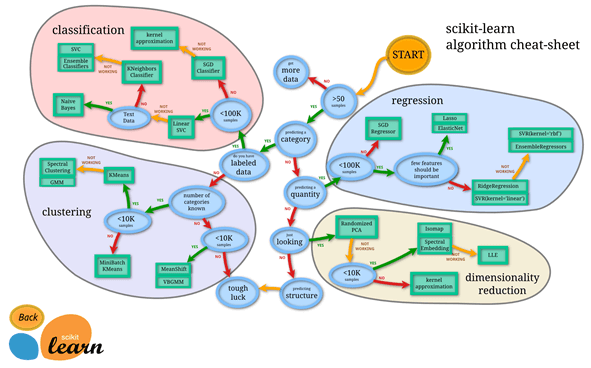
Desde Scikit-learn.org
Como estamos en el área de clasificación de texto, implementemos un Modelo ingenuo de Bayes para ver si hay potencial en este enfoque. Es un modelo bastante simple (de ahí la parte «ingenua»), pero el hecho de que nuestro conjunto de características sea bastante simple significa que podría emparejarse bastante bien con eso.
No entraré en detalles sobre cómo aplicar este modelo, aparte de compartir cómo lo implementaría en Python usando el paquete scikit-learn, la razón es que quiero ilustrar que es posible aprovechar el poder del aprendizaje automático capacidades predictivas en solo unas pocas líneas de código. *
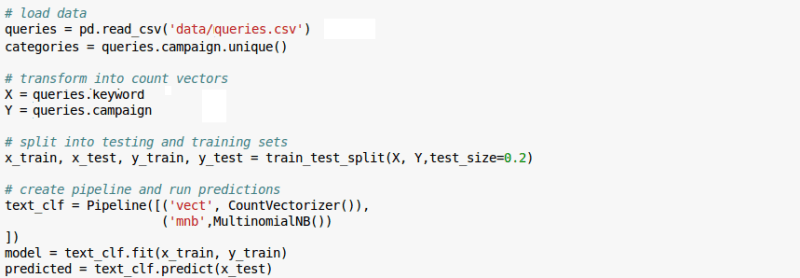
A continuación se muestra una captura de pantalla bastante emocionante de mi Cuaderno Jupyter pasando por los pasos clave de:
- cargar los datos con los que construir el modelo (~ 20.000 frases clave, preclasificadas);
- dividir mis datos en subconjuntos de entrenamiento y prueba (esto es necesario para que podamos «probar» que nuestro modelo realmente predecirá sobre datos futuros y no solo describirá datos históricos);
- creando una tubería básica que una) crea las características como se discutió (CountVectorizer) y segundo) aplica el método seleccionado (MultinomialNB); y
- predecir valores para el conjunto de «prueba» y medir qué tan preciso es el etiquetado frente a los valores «verdaderos».
* La advertencia aquí es que no soy un desarrollador, sino un matemático que programa como un medio para un fin matemático.
Conclusión
Entonces, ¿Qué tan efectivo es esto? Usando una simple medida de precisión, este método correctamente etiquetado / categorizado 91 por ciento de frases clave «nuevas» (4.431 de 4.869).
Si bien esto podría considerarse un resultado decente, haríamos muchos más ajustes y pruebas antes de poner en práctica un modelo como este.
Sin embargo, Creo que proporciona suficiente evidencia de que este es un enfoque relevante que se puede llevar adelante para mejorar y automatizar procesos, logrando así el objetivo de ganar eficiencia a escala a través de decisiones confiables y repetibles.
Las opiniones expresadas en este artículo pertenecen al autor invitado y no necesariamente a El Blog informatico. Los autores del personal se enumeran aquí.